19157628936
[email protected]
时间:2023-03-13 11:41:03

作者:景联文科技

浏览: 次
当前,ChatGPT已可以对大部分问答做到“对答如流”。但ChatGPT本质上是一个应用在对话场景的语言模型,它能够回答问题、承认错误以及拒绝不适当的请求,是预训练模型驱动的产物。它回答的准确度与训练模型的成熟度、完善度有着密不可分的关系。

当被提问“2023年在中国会是买房的好时机吗? ”“哪只股票会涨时,ChatGPT无法给出确定专业的回答,它会提示了解当前的经济形势及咨询专家建议。
当被提问“李白和苏轼谁的成就更高”,ChatGPT只能给出较为中立的回答。
当被提问“有哪些文本识别开源数据集?”,ChatGPT也只能给出信息型回复,无法告知最终结果和获取方式。
可以看出,ChatGPT对以上问题给出的答案,不过是将海量的资料重新进行排列组合,并没有超出人类目前的思维水平。而在某些问题的回答上,它虽然给出了相对不错的建议,但在有些答案上就不免显得十分“口水化”,无法作出针对性的回答。
想要ChatGPT给出更加精准的回答,就需要对其语言模型进行训练。高质量的人工标注数据是使得ChatGPT变得更加智能的关键所在。
景联文科技作为长三角地区规模最大的AI基础数据服务商之一,拥有千人从业经验丰富的数据标注团队及丰富的文本标注经验,可为NLP领域提供数据采集和数据标注服务,根据客户需求迅速调配有相关经验的标注员。
现有数据库拥有文本成品数据集200T,包括NLP、TTS、NLU、ASR、发音字典等。
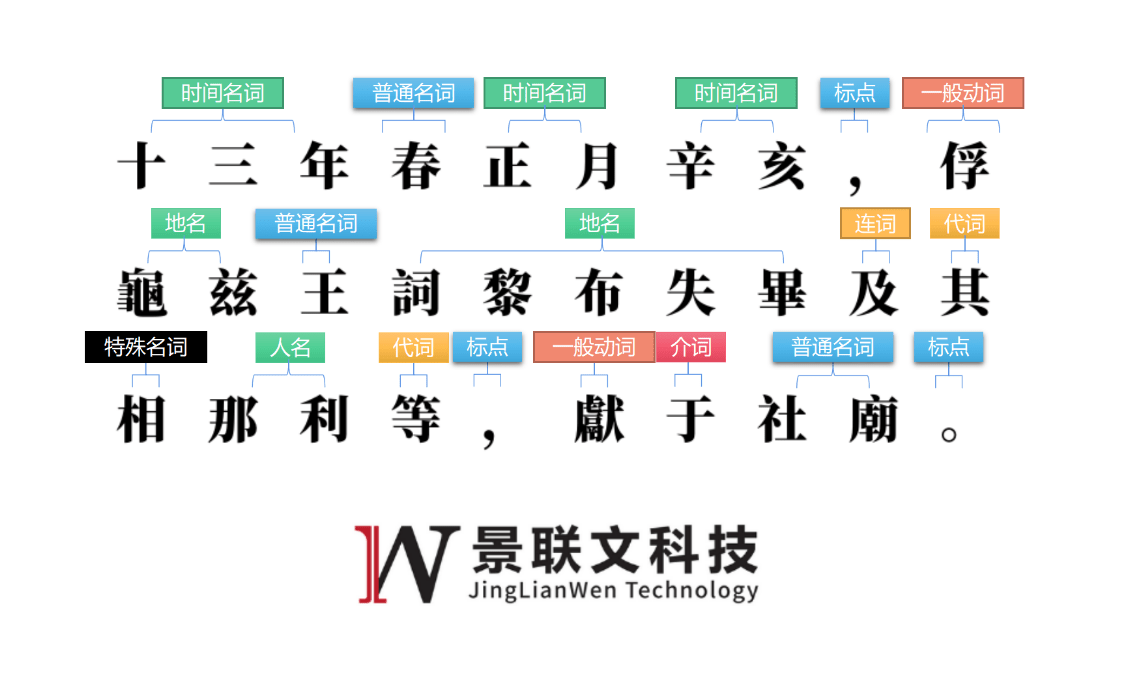
针对数据定制标注服务,景联文科技自建先进的数据标注平台与成熟的标注、审核、质检机制,支持自然语言处理:文本清洗、OCR转写、情感分析、词性标注、句子编写、意图匹配、文本判断、文本匹配、文本信息抽取、NLU语句泛化、机器翻译等多类型数据标注。
景联文科技提供的产品为全链条AI数据服务,从数据采集、清洗、标注、到驻场的全流程、垂直领域数据解决方案一站式AI数据服务,协助人工智能企业解决整个人工智能链条中数据标注环节的相对应问题。
景联文科技|数据采集|数据标注
助力人工智能技术,赋能传统产业智能化转型升级
文章图文著作权归景联文科技所有,商业转载请联系景联文科技获得授权,非商业转载请注明出处。
 在线
在线




 客户咨询电话:19157628936
客户咨询电话:19157628936 邮箱:
邮箱: 地址:杭州市萧山区杭州湾信息港E幢7楼
地址:杭州市萧山区杭州湾信息港E幢7楼
