19157628936
[email protected]
时间:2023-09-13 13:46:09

作者:景联文科技

浏览: 次
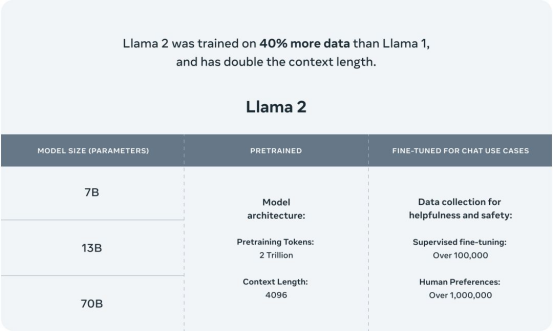
Llama 2是Meta AI正式发布的最新一代开源大模型,达到了2万亿的token。精调Chat模型是在100万人类标注数据上训练。Llama 2在包括推理、编码、精通性和知识测试等许多外部基准测试中都优于其他开源语言模型。
Llama 2开启了全球范围内AI大型模型的共享新篇章。它包括了模型权重和用于预训练和微调的Llama语言模型的起始代码,参数范围从70亿到700亿不等。相比于上一代模型,Llama 2采用了更多的训练数据,并且将context length直接翻倍,达到了4096。此外,Llama 2在人类的评判下与目前主流的模型相比占据上风,其中包括了在上下文长度为4K下的单轮与多轮对话。
Llama 2在预训练设置和模型架构上和一代模型非常相似。
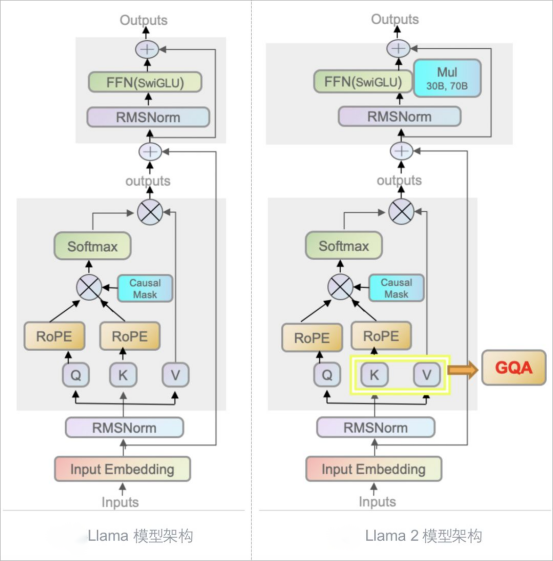
如图所示,Llama系列模型都使用了自回归Transformer架构,即Transformer's decoder-only架构。两代模型之间保持了一致性。这种一致性体现在以下方面:
预归一化(Pre-normalization):对每个transformer的子层输入都进行归一化处理,使用RMSNorm归一化函数,以确保模型更加稳定和高效地训练。
SwiGLU激活函数:在前馈神经网络(FFN)使用SwiGLU 激活函数,以替换Transformer中的 ReLU 激活函数,从而提高了模型的性能表现。
旋转嵌入编码(Rotary Positional Embeddings,RoPE):RoPE允许模型同时处理相对位置和绝对位置的信息,从而提高模型的泛化能力。这种技术的使用有助于模型更好地理解和处理序列信息。
数据是模型效果提升的关键,Llama 2不仅是在训练数据量的层面相比上一代Llama 1增加了40%,数据的来源和丰富性也得到了显著的增强。
数据质量对Llama 2模型的影响非常显著。如果使用质量不高的开源对话数据,会导致模型效果不佳。相反,如果使用质量更高的对话数据,模型效果会显著提升。因此,Meta在训练Llama 2模型时,对数据进行了严格的筛选,选择了高质量的对话数据。
此外,不同的数据源会对微调后的结果产生显著影响,这也进一步凸显了数据质量的重要性。为了验证数据质量,Meta认真考察了180条样本,并比较了经过人工审核的模型生成结果和人类自己编写的结果。结果显示,经过人工审核的数据与人类编写的数据相比也是具有竞争力的,这意味着高质量的数据对于训练对话模型至关重要。因此,Meta在训练Llama 2模型时,花费大量精力收集了高质量的人类反馈数据。
通过增加数据量、提高数据质量、增加数据多样性和改进数据标注等措施,可以显著提高模型的效果和性能,使模型达到最佳效果,从而构建更加智能、高效、准确的AI应用。
只有高质量的数据才能使模型学习到正确的语言规则和语法,减少出现偏见和误解的可能性;来自多种来源和背景的数据可以增加模型的泛化能力,使其能够适应不同的场景和语言风格;正确的数据标注对于模型的训练也是非常重要的,因为它可以帮助模型更好地理解输入数据的含义和目标,从而更好地生成输出。
景联文科技拥有丰富的文本数据采集标注项目经验,可为AI大模型提供文本相关数据采集和数据标注服务。自有的数据管理平台,支持自然语言处理:文本清洗、OCR转写、情感分析、词性标注、句子编写、意图匹配、文本判断、文本匹配、文本信息抽取、NLU语句泛化、机器翻译等多类型数据标注。打通数据闭环,可有序进行数据分发、清洗、标注、质检、等环节,交付高质量的训练数据,提高企业AI数据训练效率,加速人工智能相关应用的落地迭代周期。

景联文科技|数据采集|数据标注
助力人工智能技术,赋能传统产业智能化转型升级
文章图文著作权归景联文科技所有,商业转载请联系景联文科技获得授权,非商业转载请注明出处。
 在线
在线




 客户咨询电话:19157628936
客户咨询电话:19157628936 邮箱:
邮箱: 地址:杭州市萧山区杭州湾信息港E幢7楼
地址:杭州市萧山区杭州湾信息港E幢7楼
