19157628936
[email protected]
时间:2023-09-25 17:21:11

作者:景联文科技

浏览: 次
大语言模型在诸多下游任务中展现出令人瞩目的能力,然而在运用过程中仍然存在一些问题。幻觉现象是目前阻碍大模型成功应用的关键问题之一。
什么是大模型幻觉问题?
大模型幻觉问题是指一些人工智能模型在面对某些输入时,会生成不准确、不完整或误导性的输出。这种问题通常出现在一些大型的语言模型中,如ChatGPT等。
这些大模型在处理输入时,会根据大量的训练数据学习语言规则和模式,生成看似合理和准确的回答。然而,在某些情况下,这些模型可能会过于自信地回答问题,或者在回答中包含不准确的信息。
例如,当用户向这些大模型询问一些具有争议性或模糊性的问题时,这些模型可能会给出具有误导性的回答,这些回答可能与其训练数据中的某些特定样本有关,而并非所有情况下的准确回答。
此外,这些大模型的输出也可能存在语义上的不连贯性或逻辑上的不严密性,或大模型生成的回复与公认的事实知识出现了冲突,导致用户难以理解或信任其答案。
AI幻觉的产生原因:
l 数据偏差:人工智能系统的训练数据可能存在偏差或不一致,导致其在对新数据进行分类或预测时出现错误。这可能是因为训练数据没有涵盖某些情况或缺乏足够的代表性。
l 高维统计现象:高维统计现象可能导致人工智能系统在处理复杂数据时出现幻觉。随着数据维度的增加,数据的变化性和复杂性也相应增加,这可能使人工智能系统在处理这些数据时出现偏差。
l 训练数据不足:人工智能系统的训练数据可能不足以支持其对新数据进行准确的分类或预测。训练数据的数量和质量对人工智能系统的性能有着至关重要的影响,如果训练数据不足,则可能导致其在处理新数据时出现幻觉。
l 算法缺陷:人工智能系统的算法可能存在缺陷,导致其对新数据进行分类或预测时出现错误。例如,某些算法可能过于依赖某些特征,而忽略了其他更重要的特征,从而可能导致分类或预测的偏差。
l 应用场景不当:人工智能系统的应用场景可能不适用于其训练的模型,导致其在处理新数据时出现幻觉。例如,一个人工智能系统可能被训练用于识别图像中的物体,但如果将其应用于识别语音,则可能出现幻觉。
为了解决这些问题,我们需要针对特定领域和场景进行更加精细的训练和调整,以提高模型的准确性和可靠性。
景联文科技AI幻觉对应方案:
l 针对数据偏差问题,可以通过增加训练数据的数量和多样性来解决。训练数据需要涵盖更多的场景和情况,以减少数据偏差对AI系统性能的影响。此外,还可以采用数据清洗和预处理方法,去除或平滑掉训练数据中的噪声和异常值。
l 针对高维统计现象,可以通过采用更加复杂的模型和算法来解决。例如,可以使用深度学习模型来处理高维数据,并利用其自动学习能力来识别和应对高维统计现象。
l 针对训练数据不足的问题,可以通过应用不同的转换或操作来人工增加训练数据。例如,在图像识别任务中,可以使用旋转、缩放、裁剪等操作来增加图像数量和多样性。
l 针对算法缺陷问题,可以通过改进模型结构和算法来解决。例如,在深度学习中,可以使用更复杂的网络结构、正则化方法、优化算法等来提高模型的性能和稳定性。
l 针对应用场景不当的问题,需要仔细评估AI系统的适用范围和应用场景。例如,对于语音识别任务,需要选择适合的算法和应用场景,以避免出现幻觉。
训练数据的质量是重中之重。景联文科技致力于为AI大模型提供多样化高质量的结构化数据。

拥有全自研的标注平台,涵盖大部分主流标注工具,支持自动标注和AI预标注,经过多年打磨,交互流畅、高效。数据标注平台支持自然语言处理:OCR转写、文本信息抽取、NLU语句泛化、词性标注、机器翻译、情感判断、意图判断、指代消解、槽位填充等多类型数据标注。
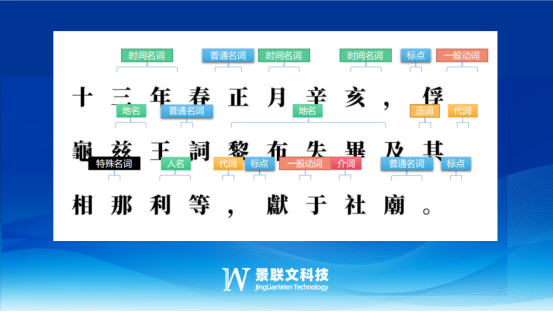
根据项目难易程度配备拥有多年NLP标注项目管理经验的项目经理和标注团队;根据项目要求进行项目结构分析,基于WBS原理将项目按照其内在结构和实施过程的顺序进行逐层分解成树状图,形成相对独立、易于管理和检查的项目各单元项目责任、进度等具体地落实到本项目每个参与者,确保标注质量。
景联文科技数据标注平台打通数据闭环,有序进行数据分发、清洗、标注、质检、交付等环节,严格监控项目进度,保证数据质量合格,极大加速人工智能相关应用的落地迭代周期,提高企业AI数据训练效率,促进人工智能产业的快速发展,实现AI应用的规模化落地效果的显著提升。

景联文科技|数据采集|数据标注
助力人工智能技术,赋能传统产业智能化转型升级
文章图文著作权归景联文科技所有,商业转载请联系景联文科技获得授权,非商业转载请注明出处。
 在线
在线




 客户咨询电话:19157628936
客户咨询电话:19157628936 邮箱:
邮箱: 地址:杭州市萧山区杭州湾信息港E幢7楼
地址:杭州市萧山区杭州湾信息港E幢7楼
