19157628936
lx@jinglianwen.com
时间:2024-04-22 09:57:02

作者:景联文科技

浏览:1044 次
OCR是计算机视觉的一种应用,它使机器能够查找和提取图像中嵌入的文本。OCR正在爆炸性增长,因为它们有可能降低人工和人为错误的成本,并提高生产力和安全性。
OCR的真实例子有很多:
许多自动设备要求能够以标牌、警告和表面嵌入式指令的形式阅读文本,房地产和金融服务等行业希望减少或消除人为参与数字化业务文档和其他工件以及以电子方式捕获其中的关键业务内容。
同样,许多行业正在寻求消除人工标注和处理手写内容的需要,例如患者图表、带标注的文本文档,其他示例包括车牌识别、菜单数字化、语言翻译等等。
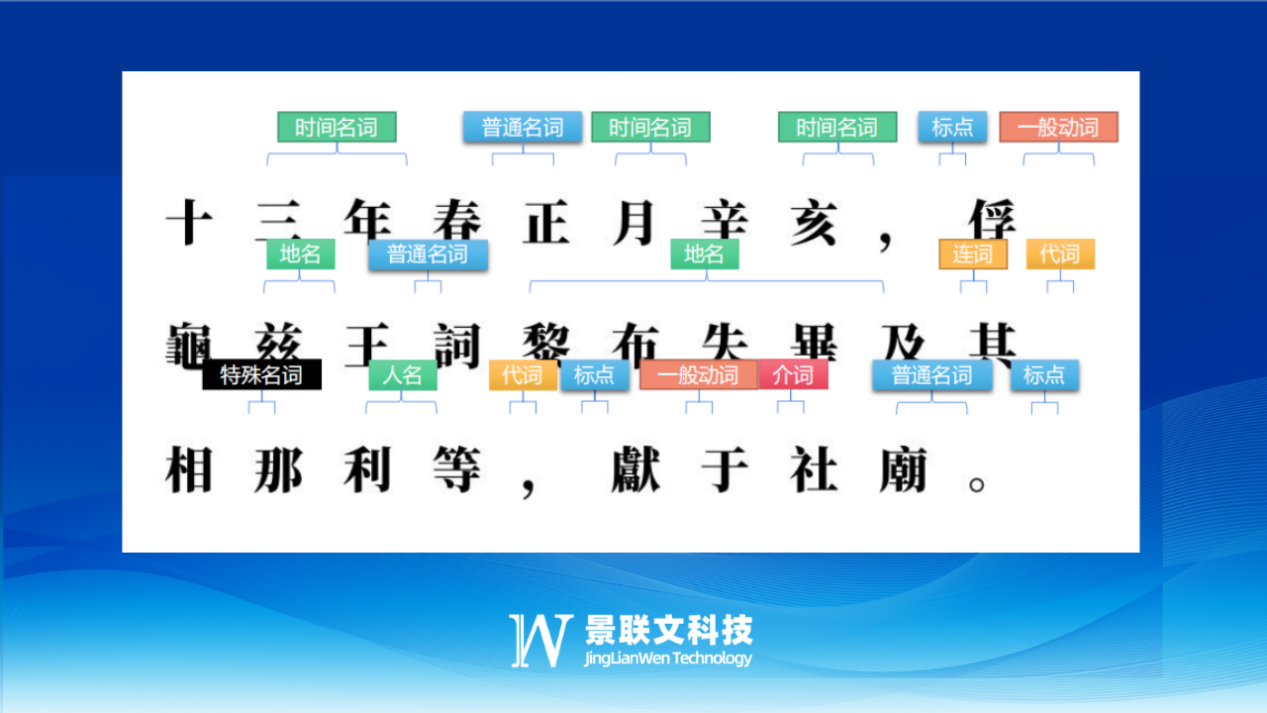
OCR模型是机器学习模型的一个子集,深度学习OCR越来越成为数据科学家的首选方法。现实世界OCR任务的复杂性和细微差别为深度学习模型提供了可观的性能优势。
深度学习模型不会自我训练。他们需要训练数据、反馈和重构,以实现最佳结果。事实上,它们的性能优势是有代价的:与许多其他ML方法相比,深度学习OCR需要的训练数据要多得多,通常要多几个数量级。
OCR涉及两个步骤,OCR模型必须在这两个步骤中都进行训练。经过训练的模型必须识别图像中文本的位置,称为文本检测,并且它必须执行文本识别,即提取文本内容。
人工数据标注器通常使用边界框或多边形对输入图像进行标注,以定位文本区域。特定应用程序可能要求它们分别标注不同的文本区域。
标记和标注只是训练数据准备的最后一步。许多数据科学团队使用的数据集合包括扭曲、倾斜或光线或大小不一致的输入图像。
数据是OCR技术发展的基石,通过收集和分析大量真实场景下的数据,OCR技术可以不断提高识别准确率,扩展识别范围,应对复杂场景,并实现实时更新与适应。
景联文科技自研数据标注平台,涵盖大部分主流标注工具,支持自然语言处理:OCR转写、文本信息抽取、NLU语句泛化、词性标注、机器翻译、情感判断、意图判断、指代消解、槽位填充等多类型数据标注。
数据标注平台打通数据闭环,有序进行数据分发、清洗、标注、质检、交付等环节,严格监控项目进度,保证数据质量合格,极大加速人工智能相关应用的落地迭代周期,提高企业AI数据训练效率,促进人工智能产业的快速发展,实现AI应用的规模化落地效果的显著提升。
 在线
在线




 客户咨询电话:19157628936
客户咨询电话:19157628936 邮箱:
邮箱: 地址:杭州市萧山区杭州湾信息港E幢7楼
地址:杭州市萧山区杭州湾信息港E幢7楼
