19157628936
[email protected]
时间:2024-06-21 11:32:00

作者:景联文科技

浏览: 次
近年来,大语言模型的发展极大推动了自然语言处理领域的进步,大语言模型正引领智能对话领域进入一个全新时代,不仅提升了对话体验的自然度和效率,也为探索更加人性化、智能化的交互方式开辟了道路。

景联文科技作为大语言模型数据服务商,提供海量优质大语言模型数据集,致力于为不同训练阶段的算法精准匹配高质量数据资源。
结合用户需求场景,构建高质量多轮对话数据库,累计2万人共创5000多万轮高质量对话数据库,并对数据库进行了规则制定、数据制造指导、排查、筛重、复核等加工环节,由专人对所有的语料进行模拟编撰,每一个环节都有专人审核,形成一个完整的质量保证体系。
产品数量
文本多轮对话1500万
中英文剧本(电影、电视剧、剧本杀)6万
平行语料:英译其他47语种,1.1亿对;中译其他50语种,2.1亿对;英中950万对。
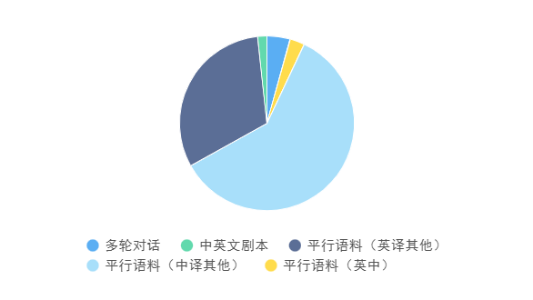
内容领域分布
对轮对话数据库覆盖多行业,包含电信行业、电商行业、教育行业、金融行业、心理咨询、医疗行业、法律援助、剧情类对话、谜语/脑筋急转弯等。
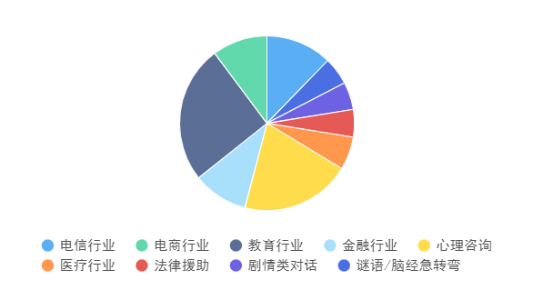
数据样例

所有数据均提供word、txt、json 格式,均经过严格流程把关,数据准确率99%,重复率低于1%。
景联文科技具备强大的技术实力和丰富的经验,完善的基础设施和专业的技术团队,为对话数据集创作者们提供稳定、高效的在线创作平台。
在技术方面,我们提供丰富的创作工具和提示词库,满足不同领域创作者的需求,让每个人都能发挥自己的创意。
在服务方面,我们提供全面的数据分析和反馈机制,帮助创作者们更好地了解创作过程和成果,不断优化和提升创作质量。
同时,拥有自己的“敏感词数据库”,可以有效避免出现敏感词而造成不必要的法律纠纷。
获取样例请登录景联文科技官网咨询客服。/ai/
或直接发送需求至邮箱:[email protected]
景联文科技|数据采集|数据标注|多轮对话数据库
助力人工智能技术,赋能传统产业智能化转型升级
文章图文著作权归景联文科技所有,商业转载请联系景联文科技获得授权,非商业转载请注明出处。
 在线
在线




 客户咨询电话:19157628936
客户咨询电话:19157628936 邮箱:
邮箱: 地址:杭州市萧山区杭州湾信息港E幢7楼
地址:杭州市萧山区杭州湾信息港E幢7楼
