19157628936
[email protected]
时间:2024-07-22 09:37:43

作者:景联文科技

浏览: 次
国内应用层面的需求推动AI产业的加速发展。根据IDC数据预测,预计2026年中国人工智能软件及应用市场规模会达到211亿美元。
数据、算法、算力是AI发展的驱动力,其中数据是AI发展的基石,中国的数据规模增长速度预期将领跑全球。

2024年《政府工作报告》中明确提出开展“人工智能+”行动,旨在深化AI技术在各行业的融合与应用。
伴随人工智能领域大模型技术的快速发展,各级政府纷纷出台激励政策,加快大模型产业的持续发展。时至今日,北京、上海、广东、安徽、福建和深圳、杭州、成都等地均颁布了旨在扶持AI大模型的相关产业政策。
在大模型数据集的构建过程中,数据的质量和多样性是核心要素。只有高质量、多样化的数据,才能训练出更加准确、泛化能力更强的模型。
景联文科技是大语言模型数据供应商,拥有海量高质量大模型数据资源。
世界知识类期刊及高价值社区文本数据:
高质量外文文献期刊8500万篇、英文高质量电子书200万本
教育题库:
K12教育题库1800万、大学题库1.1亿,800万带解析、英文题库500万
专业知识类专利、代码:
中文数字专利4000万、程序代码(代码注释)20万
多轮对话:
文本多轮对话1500万、中英文剧本(电影、电视剧、剧本杀)6万
音频数据:
普通话65万小时
图片生成及隐式/显示推理多模态数据:
图文复杂描述600万、图文推理问答对600万
生物数据:
核酸库4000万、蛋白库50万、蛋白结构库19万、通路库1000万、生信工具
药学数据:
药物研发数据库1300万、全球上市数据库80万、一致性评价数据库25万、生产检验数据库40万、合理用药300万、多维文献1亿、原料药数据库1100万

化学数据:
化合物数据库1.6亿、反应信息数据库4100万、物化性质数据库1.6亿、谱图数据库20万、晶体信息数据库100万、安全信息数据库180万、商品信息数据库740万

材料数据:
金属材料数据20万、纳米材料数据30万、相图数据6万、材料性能数据20万、材料腐蚀数据、表面处理数据、焊接材料数据

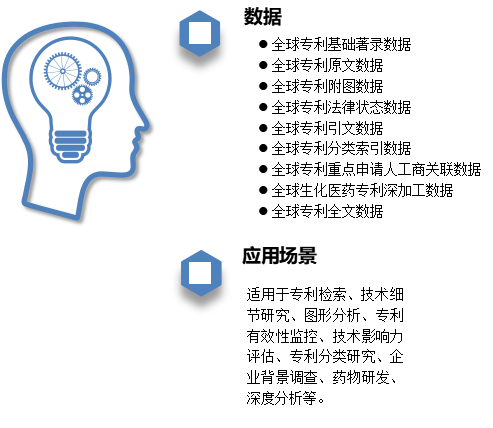
专利数据:
全球专利基础著录数据1.3亿、全球专利原文数据1亿、全球专利附图数据、全球专利法律状态数据、全球专利引文数据、全球专利分类索引数据、全球专利重点申请人工商关联数据、全球生化医药专利深加工数据、全球专利全文数据
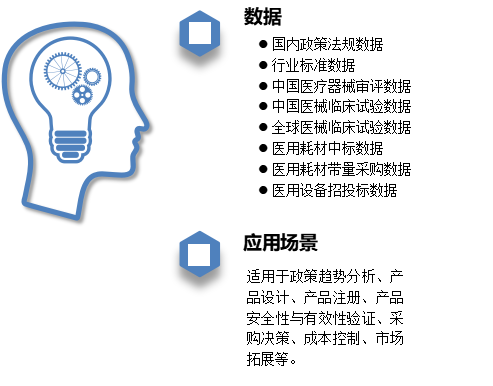
医疗器械数据:
国内政策法规数据3千条、行业标准数据、中国医疗器械审评数据20万条、中国医械临床试验数据5千条、全球医械临床试验数据7万、医用耗材中标数据1400万、医用耗材带量采购数据400万、医用设备招投标数据38万
随着数据量的不断增加,如何高效地存储、管理和利用这些数据也成为了亟待解决的问题。
景联文科技通过分布式存储和计算技术,可以实现数据的高效存储和快速处理;拥有丰富的多领域专家资源,所有数据都经专业人员进行三轮质检,数据准确率可达99%,可加速算法研发进度,为各领域大模型的训练和优化提供有力支持。
在数据安全与合规方面,景联文科技已通过ISO9001质量、ISO27001信息安全、ISO27701国际隐私安全管理认证,积极参与8项国家数据交换格式和数据安全标准制定,牢固构筑数据保护的基石。
景联文科技|数据采集|数据标注|大模型训练数据
助力人工智能技术,赋能传统产业智能转型升级
文章图文著作权归景联文科技所有,商业转载请联系景联文科技获得授权,非商业转载请注明出处。
 在线
在线




 客户咨询电话:19157628936
客户咨询电话:19157628936 邮箱:
邮箱: 地址:杭州市萧山区杭州湾信息港E幢7楼
地址:杭州市萧山区杭州湾信息港E幢7楼
