19157628936
[email protected]
时间:2024-08-16 11:05:46

作者:景联文科技

浏览: 次
在图像处理和计算机视觉领域中,将一张图像转化为可用于训练机器学习模型的数据是一项复杂而重要的任务。SFT(Supervised Fine-Tuning,监督微调)是一种常见的深度学习策略,在这一过程中发挥着核心作用。
SFT是指在一个预训练好的模型基础上,利用带有标签的新数据集对其进行进一步训练的过程。通过构建高质量的SFT数据集,可以提升模型在特定任务上的表现。

如何构建高质量SFT数据集以适应特定任务或领域?
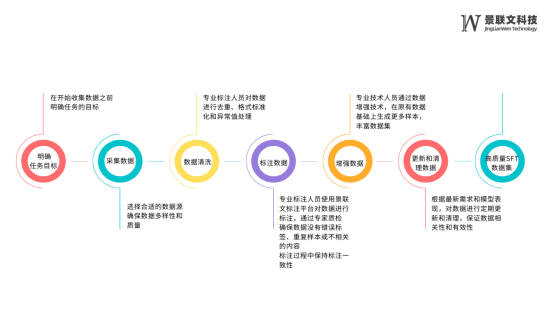
1. 明确任务目标:定义具体问题或任务类型,并选择合适的评估指标。
2. 采集数据:选择合适的数据源,确保数据多样性和质量。数据应涵盖任务中可能遇到的各种场景。
3. 数据清洗:进行去重、格式标准化和异常值处理。
4. 标注数据:制定详细的标注规则,使用适当的标注工具,并通过专家审核确保准确性。确保数据没有错误的标签、重复的样本、或者不相关的内容。
5. 增强数据:通过数据增强技术,在原有数据基础上生成更多样本,从而丰富数据集。
6. 定期更新和清理数据:根据最新的需求和模型表现进行定期更新和清理,以保证数据的相关性和有效性。
7. 法律与伦理考虑:确保数据处理符合法律法规要求,并保护个人隐私。
构建高质量的SFT数据不仅能够显著提高模型的性能和实用性,还能够降低开发过程中的风险和成本,同时增加模型的可信赖度。
景联文科技构建SFT数据集
景联文科技提供SFT数据服务
景联文科技是AI数据服务公司,提供SFT数据服务。
通过构建多层次的标注团队——包括粗标、精标及专业级标注人员,有效满足各种特定任务和专业领域对于SFT数据的需求。助力提升模型的逻辑推理能力、处理复杂指令的能力,增强模型在面对敏感问题时的应答能力。
为客户提供用于监督微调的高质量数据集,包括数据清洗、标注和格式转换等。
适用场景:
文本分类:如情感分析、主题分类等。
文本生成:如文章写作、对话生成等。
问答系统:如智能客服、知识图谱查询等。
聊天机器人:如客服机器人、虚拟助手等。
景联文科技提供高质量SFT数据集
景联文科技提供海量优质大模型数据集,可用于SFT数据服务。
世界知识类期刊及高价值社区文本数据数千万篇:高质量外文文献期刊 、英文高质量电子书
教育题库数亿道:K12教育题库、大学题库,带解析、英文题库、专业知识类期刊、专利、代码、中文数字专利、程序代码(代码注释)
多轮对话数千万:文本多轮对话、中英文剧本(电影、电视剧、剧本杀)
音频数据数十万小时:普通话
图片生成及隐式/显示推理多模态数据数百万:图文复杂描述、图文推理问答对
生物数据数千万:核酸库、蛋白库、蛋白结构库、通路库、生信工具
药学数据数亿:药物研发数据库、全球上市数据库、一致性评价数据库、生产检验数据库、合理用药 、多维文献、原料药数据库
化学数据数亿:化合物数据库、反应信息数据库、物化性质数据库、谱图数据库、晶体信息数据库、安全信息数据库、商品信息数据库
材料数据数十万:金属材料数据、纳米材料数据、相图数据、材料性能数据、材料腐蚀数据、表面处理数据、焊接材料数据
专利数据数亿:全球专利基础著录数据、全球专利原文数据、全球专利附图数据、全球专利法律状态数据、全球专利法律状态数据、全球专利引文数据、全球专利分类索引数据、全球专利重点申请人工商关联数据、全球生化医药专利深加工数据、全球专利全文数据
医疗器械数据数千万:国内政策法规数据、行业标准数据、中国医疗器械审评数据、中国医械临床试验数据、全球医械临床试验数据、医用耗材中标数据、医用耗材带量采购数据、医用设备招投标数据
在数据安全与合规方面,景联文科技已通过ISO9001质量、ISO27001信息安全、ISO27701国际隐私安全管理认证,积极参与8项国家数据交换格式和数据安全标准制定,牢固构筑数据保护的基石。
登录景联文科技官网咨询客服。https://www./ai/
或直接发送需求至邮箱:[email protected]
景联文科技|数据采集|数据标注|大语言模型训练数据
助力人工智能技术,赋能传统产业智能转型升级
文章图文著作权归景联文科技所有,商业转载请联系景联文科技获得授权,非商业转载请注明出处。
 在线
在线




 客户咨询电话:19157628936
客户咨询电话:19157628936 邮箱:
邮箱: 地址:杭州市萧山区杭州湾信息港E幢7楼
地址:杭州市萧山区杭州湾信息港E幢7楼
