19157628936
[email protected]
时间:2024-11-15 15:04:55

作者:景联文科技

浏览: 次

随着大型语言模型(LLMs)在自然语言处理领域的广泛应用,如何高效地利用有限的数据资源来优化模型性能成为了一个重要的研究方向。
今天精选了5篇关于数据选择与高质量数据集构建方法的代表性文章。它们分别从不同的角度探讨这一话题。为便于大家阅读,我们仅列出文章标题、主要内容概要以及核心要点。如果您对某篇文章感兴趣,可以点击后面的链接访问完整内容。
一、【LLM模型微调】LLMs-数据筛选-DEITA-231225论文总结v4.0
本文重点解读了DEITA [ICLR2024] 论文,探讨了其在指令调优中自动数据选择的方法。引入了基于模型嵌入距离的多样化数据选择方法。实验结果显示,DEITA模型在少量数据下表现出优越性能,证实了数据选择在模型对齐中的关键作用。
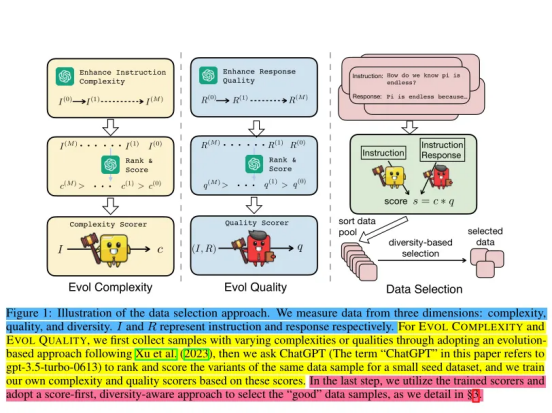
通过系统地探索数据的复杂性、质量和多样性三个维度,DEITA提出了一套基于进化复杂度(EVOL COMPLEXITY)和进化质量(EVOL QUALITY)的自动数据选择策略,以及一种基于模型嵌入距离的多样性筛选方法。这些方法不仅能够自动识别和选择对模型性能提升最有效的数据样本,而且显著提高了指令微调的数据效率。
实验结果表明,使用DEITA方法选择的数据样本训练出的模型,在多个评估基准上(如MT-Bench、AlpacaEval和Open LLM Leaderboard)的表现优于或与现有最先进的开源对齐模型相当,尤其是在使用较少训练数据的情况下。
DEITA项目不仅开源了模型和数据集,还提供详细的实验设置和训练细节,为未来的相关研究提供了宝贵资源和支持。DEITA模型在不同数据量下始终提供了最佳的数据选择性能。强调了数据选择在模型训练中的重要性。
作者:Theseyouwant
链接:https://mp.weixin.qq.com/s/lbF8Xin_Lcz3M3JDzniihw
二、60条数据就能教会大模型知识问答! | 探索大模型在问答任务上的微调策略
本文通过一系列实证分析,探讨了大语言模型(LLMs)在问答(QA)任务中的监督微调(SFT)策略。研究发现,仅需60条数据,LLMs就能有效激活预训练时编码的知识,高质量地完成QA任务。
不同知识记忆层次的数据对模型表现有显著影响,使用高记忆水平的数据进行微调能显著提升模型的整体表现。此外,不同LLMs在SFT阶段对数据的需求存在差异,这与其预训练语料库的差异有关。研究团队设计了一种多模板补全机制,能够可靠地评估预训练LLMs对不同知识的记忆程度。实验结果为制定更有效的微调策略提供新的见解,并为进一步研究LLMs的潜在机制奠定基础。

作者:FudanNLP
链接:https://mp.weixin.qq.com/s/bsokm0bMoRhGEn8AKEK1yw
三、大模型预训练中的数据处理及思考
本文探讨了大模型预训练中的数据处理关键点,包括数据来源、清洗方法、对模型性能的影响及数据量的天花板。强调了专有数据和网页数据在模型训练中的作用,以及数据处理在提升模型效果中的重要性。
文章介绍了名为DEITA的新方法,专注于大模型微调阶段的指令数据筛选,强调了数据质量和多样性的关键作用。DEITA的核心理念是“Score-First, Diversity-Aware Data Selection”,即首先对数据的复杂性和质量进行评分,然后根据多样性筛选数据。
该方法首先对小规模种子数据集进行复杂性和质量的扩展,使用ChatGPT评分并训练Llama模型以对全量数据进行评分。接下来,通过计算新样本与已选样本间的余弦相似度来实现多样性筛选,确保筛选出的数据既具有高质又具备多样性。
实验结果显示,相较于随机数据筛选和其他SOTA模型,使用DEITA方法筛选的数据训练的模型在多个基准测试上表现更佳,尤其是在使用6K至10K样本时效果尤为显著。此方法为提高大模型微调效率和效果提供了新的思路。
作者:智猩猩Plus
链接:https://mp.weixin.qq.com/s/h1YgbWqrFCQvkJkj4BskhA
四、RAG数据集自动构造探索,附PROMPT
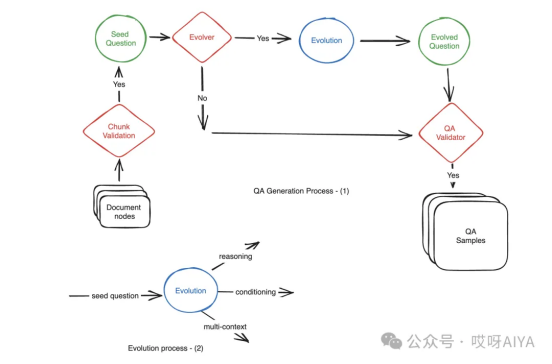
本文介绍了一种名为Ragas的工具,它使用进化生成范式自动生成多样化的问题-上下文-答案样本,以评估大型语言模型的性能,解决人工创建QA样本耗时且难以达到所需复杂度的问题。通过引入推理、多上下文、条件prompt和对话式重写等技术,增加样本复杂度,提高评估质量,减少人工创建数据的劳动强度。
Ragas利用大型语言模型(LLM)的能力,通过特定的Prompt指导模型将简单问题转换为更复杂的问题,如多跳推理问题、引入条件元素的问题、需要结合多个上下文信息的问题以及模拟聊天交互的对话式问题。每种类型的问题都有一套具体的规则来指导问题的重写,确保问题既不过于冗长也不偏离原始上下文,同时保证问题的合理性和可回答性。例如,对于多上下文问题,要求改写后的问题需要同时参考两个不同的上下文信息才能完整回答;对于条件问题,则是在问题中加入特定的场景或条件以增加其复杂性。
这种方法不仅提高了数据生成的效率,还增强了数据集的多样性和实用性,对于提升模型的训练效果和评估准确性具有重要意义。
作者:PaperAgent
链接:https://mp.weixin.qq.com/s/KfVeN_jE8xRDZvdI3-GlnA
五、大模型SFT阶段应该怎么选择数据必读论文(Data Selection for LLM Instruction Tuning)
本文探讨了在监督微调(SFT)阶段如何筛选对模型训练有帮助的数据。选择数据时应考虑三个主要方面:数据的质量、多样性和难度。文中特别提到了几篇读后有所启发的论文。
在进行SFT时,不仅要关注数据的数量,更要重视数据的质量和特性,以确保模型能够从训练中获得最佳性能提升。
作者:xihuichen
链接:https://zhuanlan.zhihu.com/p/713433670
 在线
在线




 客户咨询电话:19157628936
客户咨询电话:19157628936 邮箱:
邮箱: 地址:杭州市萧山区杭州湾信息港E幢7楼
地址:杭州市萧山区杭州湾信息港E幢7楼
